新增 "国家战略级专利"。 -专利内容具体描述:聊 GPT 评论-。 (1)通过对声音的分析和总体分析进行通知、报告和定位的专利。 (2)获得新的专利证书的第七项专利决定定稿
未来的安保和安全将发生变化。 ~专利号 7796450:与安全、防灾、预防犯罪和对策有关的专利 ~。
株式会社ポイント機構
Point 组织公司 (竹内结子株式会社(总部:东京都涩谷区千駄谷)目前正在努力获得约 30 项专利(包括计划申请、待批申请和已确认申请),并欣然宣布这将是竹内结子项目获得的第七项专利(目前:专利授权率为 100%)。这是通过竹内结树项目获得的第七项专利(目前:100% 的专利授权率得到确认)。该专利的发明人/权利人是 Point Mechanism Corporation 的总代理 K Trust Corporation(日本爱知县名古屋市守山区),竹内结子已获得该专利的使用权(包括许可权)。该专利是 Yuki Takeuchi 获得专利使用权(包括许可权)的专利。
竹内结子所属的Point Organization公司以0的成本引进了使用引进公司的原创优惠券和原创点数的系统(A-GEL系统:A-GEL礼品点数和A-GEL礼品卡,免费向商家提供最多40%的点数,用于生活支持和管理支持)。我们正在开发销售咨询公司的定位,通过引入 0.00 日元的系统(付费后的成功费用类型),为企业主实现销售额的提高和成本的降低。提出这项新专利的理由是:消除各种犯罪;在紧急情况下,通过自动通知和自动报告,确认安全和定位人员,创造一个可以进行救援和救助的环境;减少人们因他人行为而悲伤和受伤的环境;减少因汽车盗窃、破坏无人商店和自动售货机而死亡的人数;减少因他人行为而受伤的人数;减少因他人行为而死亡的人数。汽车盗窃、无人商店破坏、自动售货机破坏 "和 "让各行各业的人们都能感受到安全、微笑和保护自己幸福的未来得以实现 "的愿望而构思和设计的专利。
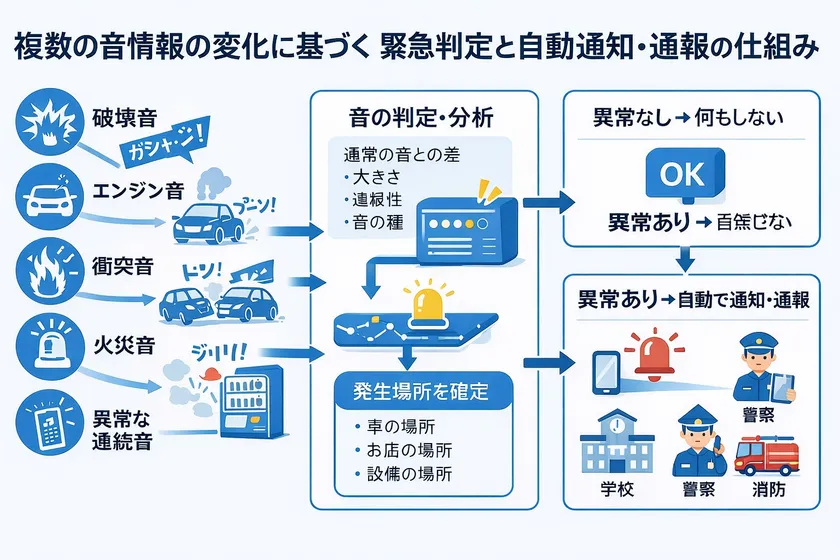
一般声音专利图片 (1)
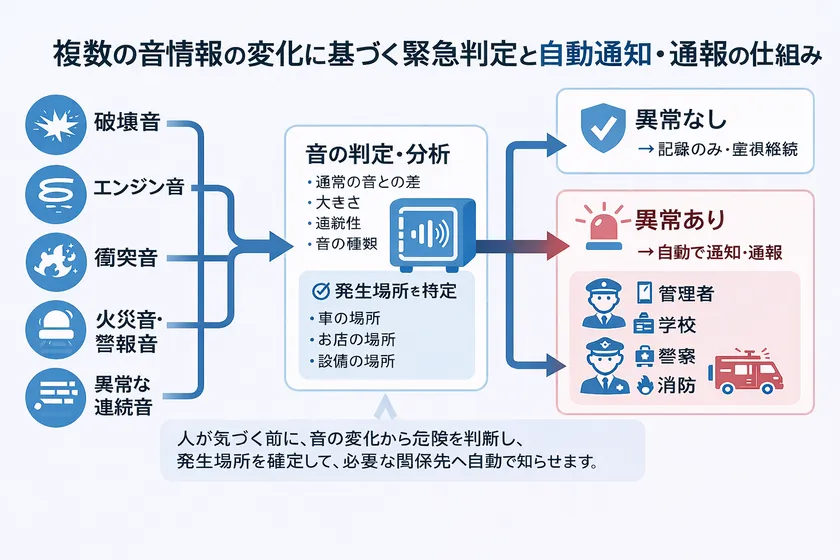
一般声音专利图片 (2)
1) 本专利保护的 "发明核心
本专利的核心内容概括在权利要求 1 中。简而言之,它通过 "声音(用户的声音+环境声音)"+"位置 "来估计情况,"搜索并选择 "与情况相匹配的 "多个联系人"(终端中/互联网上),并使用预先确定的通信方法 "自动通知 "他们。系统通过预先确定的通信方式 "自动通知"。
2) 按权利要求:权利范围(什么是足够接近/足够强大的权利)
权利要求 1(核心:侵权裁决的参考点)
基本要素(如果全部具备则 "非常接近")→"声音收集(用户声音 + 环境声音)"、"第一位置信息获取"、"存储设备:存储声音数据"、"计算设备:根据至少声音数据进行情况估计"、"根据情况进行多种联系"。"从存储设备/网络中搜索和选择"、"通信设备:通过预先定义的通信手段自动通知"。
易于渗透的典型权利:"声音(尖叫/震动/求助等)检测→情况评估→"从联系人数据库中搜索 "并自动通知家人、警察、保险、设施等"。这种 "搜索和选择 "是差异化的核心。
权利要求 2(实施地点自由:无论将设备放置在哪个物体上,都可享有该权利)
在护理床、书包、车辆、智能钥匙、钱包、书写工具、可穿戴设备等上实施。→ "不限于智能手机",因此很难通过改变产品形式来逃避。
权利要求 3(起始条件:嵌入式触发器)。
估计从 "声压高于声音数据标准 "或 "通过语音分析检测到注册关键词 "开始。→"何时开始估算 "很明确,而且此项目易于实施(=易于采用)。
要求 4(无法通过声音进行估算时的后备方案:通过距离进行紧急估算)
如果添加了第二个位置信息设备(例如父母的智能手机),并且在无法通过声音估算的情况下,距离超过了预定距离,则进行紧急估算→自动通知。→ 设计还使系统能够捕捉 "无声/难以捕捉 "的紧急情况,如被带走、走失或被遗弃。
要求 5(报告的可靠性:多通道 + 重试)
系统可通过多种通信方式分阶段或同时进行报告,如果信息传递失败,则更换通信方式,重新发送信息。→ 该领域的有力主张,消除了 "无法到达 "的问题。
主张 6(证明:估计开始时自动成像)。
在推定开始的同时开始成像。→ 易于保存事故/事件的 "前后对比",这在后期阶段(警方、保险、诉讼)非常有用。
主张 7(加密+外部存储:既可作为证据,又可保护隐私)
加密声音数据和图像数据并传输到外部服务器/云。→ 本发明实施例还说明,通信设备支持语音呼叫/邮件/短信/应用通知等多种方式,声音和图像数据可对外传输并加密。
权利要求 8(人工智能化:利用学习模型进行高级情况估计)。
基于以声音+位置为输入、以情况为输出的估算模型(有监督数据的机器学习)进行估算。→ 权利包括未来发展潜力,如减少误报、提高分类准确性、按地区/年龄/车辆类型优化等。
权利要求 9(程序权利:也可以是软件)。
一种程序,使运算单元能够执行 "基于声音(至少是声音)的情况估计"、"根据情况搜索和选择联系人 "和 "使用预先确定的通信手段自动通知"。→ 即使硬件不同,核心逻辑(软件)也是相同的,因此可以纳入范围。
3) 与传统系统的比较
传统系统往往存在 "SOS 按钮按下、应用程序启动、电话呼叫等**'个人操作'是前提**"、"固定联系人(仅限家人、仅限保安等)"和 "弱证据(记录/录音/加密存储)是事后考虑 "等问题。
本专利的优点是在权利要求 1 + 从属条款中建立了 "根据声音+位置估计情况(即使无法操作也会移动)"、"根据情况搜索和选择多个联系人(优化报告联系人)"、"传递机制(多种方式/转发)"和 "证据(开始拍摄+加密云)"。
4)问题→改进→解决方案(与权利要求的映射)。
问题 A:人无法操作系统(失去知觉、恐慌、束缚)→通过声音+位置估计情况→自动通知 (权利要求 1/9)
实施方案还说明了效果:"即使用户无法识别情况,系统也能自动向适当的联系人报告"。
问题 B:误报和模糊的启动条件 → 通过声压/关键字启动(权利要求 3)。
问题 C:无法接收声音的紧急情况(被带走/徘徊/遗落) → 距离回退(要求 4)
问题 D:未收到呼叫 → 多通道 + 重传(权利要求 5)。
问题 E:事后没有留下证据/担心被篡改 → 估算开始时成像(权利要求 6)+ 加密和外部存储(权利要求 7)
问题 F:希望提高情况估计的准确性 → 学习模型(要求 8)
5) 示例
作为实现示例,假设发生紧急情况,例如 "一个孩子被车碾压",选择保险公司(公司)和警察,打电话给警察向公司报告事故信息,必要时打电话给消防部门,开始录音/录像,并将信息发送到外部服务器/云端 "使其成为证据"。"描述了这一过程。还指出,书包不仅可用于意外事故,还可用于绑架等事件;而车载系统不仅可用于意外事故,还可用于车辆盗窃。如果将其应用到 "现实生活 "中,例如:"书包(书包/可穿戴设备):撞击声+尖叫声/关键字→自动通知家人+警察+消防员,视频/声音以加密格式存储";"护理(床/手表):跌倒声/呻吟声→自动通知设施工作人员+家人,夜间主要通知。自动通知设施工作人员 + 家属,夜间更换主要联系人"、"车内(DVR + 麦克风 + GPS):事故声音 → 保险 + 警察 + 紧急服务,同时将证据发送到云端"、"安保(商店/自动售货机/无人基地):破坏声音 → 自动通知安保公司 + 所有者,加密存储视频录像"。
(每个部分都有第 5-7 项要求的有力支持)
6) 谁使用它、它能做什么、它能做什么以及未来如何设计。
谁使用(主体)。
家庭:监控儿童/老人;设施(护理/医疗):早期发现和通知跌倒、突然变化和走失;公司(保险/安全/运输):获取事故的原始信息、保存证据和缩短初步反应时间;地方政府/学校:学校安全、社区监控网络。
使用方法(配置)
麦克风(声音)+定位(GPS 等)+计算(终端/云)+通信(电话/短信/应用通知等) → 设计指出,通信设备支持多种方式,可以向外传输声音/视频并进行加密。设计还指出,麦克风/摄像头/GPS 可与主机分开放置(有线/无线传输)。
它能做什么(效果)?
即使无法操作也能自动报告(权利要求 1/9)"、"根据情况优化(搜索和选择)报告目的地(权利要求 1/9)"、"提高到达概率(多通道、重传)(权利要求 5)"、"留下证据(图像捕捉 + 加密云)(权利要求 6 和 7)"、"提高估计精度(学习模型)(权利要求 8)
设计未来(现实的路线图)。
第 1 阶段:基于规则(从声压/关键词开始,使用固定规则估计情况)= 适合早期发布(权利要求 3),第 2 阶段:高级搜索和选择联系人(根据情况 x 一天中的时间 x 地点 x 属性进行优化)= 权利要求 1 的核心,第 3 阶段:利用学习模型减少误报(适应环境和年龄差异)= 权利要求 8,第 4 阶段:利用学习模型减少误报(适应环境和年龄差异)= 权利要求 8,第 5 阶段:利用学习模型减少误报(适应环境和年龄差异)= 权利要求 8,第 6 阶段:利用学习模型减少误报= 权利要求 8,第 7 阶段:利用学习模型减少误报= 权利要求 8。适应)= 权利要求 8","第 4 阶段:证据治理(加密存储+访问控制+保险/安全/市政合作 API)= 权利要求 6 和 7"。
本专利是一种获取并存储声音数据(包括用户周围产生的声音)和位置信息,计算设备估计紧急情况,根据估计结果选择多个联系人,通信设备自动通知和报告的机制。
声音的定义(重要且不受限制):本专利中的 "声音 "可包括以下所有内容。
本专利最大的特点是人的声音不是必需的,只能使用环境声音。这是本专利最大的特点。
I. 案例研究 (1) [汽车盗窃/车辆相关] (3 个案例)
<案例 1-A:深夜汽车盗窃(破坏性噪音 + 发动机噪音)
用户:车主/车队经理","安装目标:车辆本身","使用设备:车载设备(麦克风 + GPS + 通信)"。
声音内容
玻璃破碎声"、"撬门声"、"工具声"、"发动机启动声
判断和操作
声音数据 + 车辆位置(权利要求 1)"、"通过响亮的破坏性声音开始估算(权利要求 3)"、"通过超出与车主智能手机的距离加强紧迫性(权利要求 4)"、"通过选择车主、保安或警察自动通知(权利要求 1 和 5)"。
▼ 效果。
初始响应速度加快数分钟至数十分钟","降低车辆移除/部件移除的成功率"。
<案例 1-B:停车场发生肇事逃逸和碰撞事故
用户:车主"、"声音:碰撞声、异常撞击声"、"通过声音+位置推测事故可能性"、"通过启动图像捕捉确保证据(要求 6)"、"云存储(要求 7)" -> 肇事者识别和保险应对变得更加容易。
<案例 1-C:无人停车场内的连续破坏行为。
声音:连续的金属断裂声"。
使用机器学习模型高度准确地确定该声音不是正常声音(索赔 8)。
自动通知管理部门和警方。
可对惯犯采取行动,同时抑制误报。
二. 案例研究集 (2) [无人商店、自动售货机、破坏设施] (3 个案例)
<案例 2-A:闯入并破坏无人商店。
用户:店主/经营者 安装目标:商店内部和围墙
声音
百叶窗破碎声"、"玻璃破碎声"、"金属撞击声"、"异常连续撞击声"。
▼ 操作
声音 + 商店位置以估计 "入侵/破坏""同时/分阶段通知店主 + 保安 + 警察(索赔 5)
效果
减少犯罪继续所需的时间 "和 "控制现场反应的延误"。
<案例 2-B:自动售货机被毁(夜间,无人在场)
声音:硬币掉落声 + 破坏声
声音:硬币掉落声 + 破坏声。
即使没有人声,该系统也有效。
即使外壳被破坏,证据依然存在。
<案例 2-C:仓库或设备间内的机器损坏。
声音:不正常的机器声,持续的破坏声。
声音与正常工作声音之间的差异由学习模型确定(权利要求 8)。
自动通知管理人员和保安
三. 案例研究集(3)[人声和环境噪声混合的紧急情况](3 个案例)
<案例 3-A:夜间袭击/麻烦
声音
喊叫声"、"打斗声"、"碰撞声
关键词检测或大音量开始估算(索赔 3)"、"自动通知多个联系人(管理员、警察)"。
<案例 3-B:跌倒或突发疾病(声音 + 撞击)
声音
跌倒声、呻吟声。
通过声音 + 位置进行紧急估计
可通知家人、设施和紧急服务部门。
<案例 3-C:火灾初期(无人声)
声音
警报声"、"火灾声"。
在人们意识到火灾之前,估计火灾发生的可能性。
自动通知消防员/管理人员
最后总结(整合)
本专利在 "盗窃、破坏和无人环境 "方面具有极强的优势,因为它 "无论是否有人的声音都能工作","仅从破坏、机械和发动机的声音就能判断紧急情况","可自动选择多个联系人并进行冗余呼叫","可通过距离条件、证据和学习模型来提高准确性","可应用于车辆、无人商店、设备甚至人身安全"。这是一项紧急报警专利,对 "盗窃、破坏和无人环境 "的防范能力极强。
发明人/设计者(Yuki Takeuchi)的评论
我希望通过各种项目和发明来改善和解决各种社会问题,让日本的未来在安全保障中绽放笑容"。
目前,Yuki Takeuchi 正在开发 "A-GEL 礼品积分和 A-GEL 礼品卡 "服务,通过利用 Point Organization Co.该服务正在开发中。